
DBMS Quick Reference
Cardinality
cardinality refers to the relationship between two tables. Relationship can be of four types : 1 to 1, 1 to many, many to 1 , many to many.
ACID
A transaction is a single logical unit of work which accesses and possibly modifies the contents of a database. Transactions access data using read and write operations. In order to maintain consistency in a database, before and after the transaction, certain properties are followed. These are called ACID properties.
-
Atomicity : either the entire transaction takes place at once or doesn’t happen at all. There is no midway i.e. transactions do not occur partially
-
Consistency : This means that integrity constraints must be maintained so that the database is consistent before and after the transaction. It refers to the correctness of a database. e.g,The total amount before and after the transaction must be maintained.
-
Isolation : multiple transactions can occur concurrently. Transactions occur independently without interference
-
Durability : This property ensures that once the transaction has completed execution, the updates and modifications to the database are stored in and written to disk and they persist even if a system failure occurs. These updates now become permanent and are stored in non-volatile memory. The effects of the transaction, thus, are never lost.
Normalization
Normalization is a database design technique that reduces data redundancy and eliminates undesirable characteristics like Insertion, Update and Deletion Anomalies. Normalization rules divides larger tables into smaller tables and links them using relationships. The purpose of Normalization in SQL is to eliminate redundant (repetitive) data and ensure data is stored logically.
-
1NF : Every column/attribute should have only single value.
-
2NF : No partial funtional dependency
-
3NF : No transitive funtional dependency
-
BCNF : for any dependency A → B, A should be a super key i.e for a dependency A → B, A cannot be a non-prime attribute, if B is a prime attribute.
Indexing
Indexing is a data structure technique to efficiently retrieve records from the database files based on some attributes on which the indexing has been done.
-
Dense index : there is an index record for every search key value in the database. This makes searching faster but requires more space to store index records itself.
-
Sparse index : index records are not created for every search key. An index record here contains a search key and an actual pointer to the data on the disk. To search a record, we first proceed by index record and reach at the actual location of the data. If the data we are looking for is not where we directly reach by following the index, then the system starts sequential search until the desired data is found.
B+ tree
A B+ tree is a balanced binary search tree that follows a multi-level index format. The leaf nodes of a B+ tree denote actual data pointers. B+ tree ensures that all leaf nodes remain at the same height, thus balanced. Additionally, the leaf nodes are linked using a link list; therefore, a B+ tree can support random access as well as sequential access
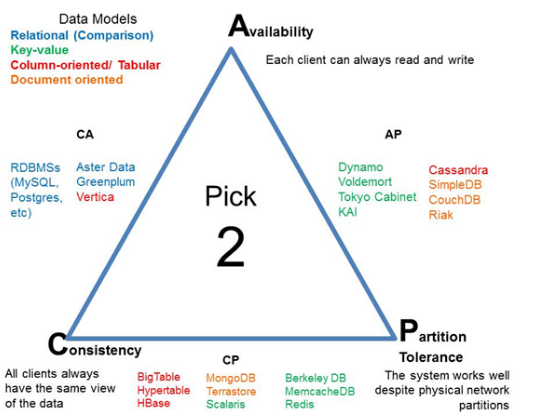
CAP theorem
CAP Theorem is a concept that a distributed database system can only have 2 of the 3: Consistency, Availability and Partition Tolerance
SQL vs NoSQL
| SQL | NoSql |
|---|---|
| Relational db, structured data | Schemaless, un/semi - structured data |
| stored in tables | can be document-oriented, column-oriented, graph-based or organized as a KeyValue store |
| Vertically Scalable | Horizontally Scalable |
| strong query language | querying tools not as sophisticated as sql |
| support Acid | Acid support varies amongst different implementations |
| Join 2 or more tables | relations are not stored in different tables, hence join is not required as such. ( mongoose populate actually does 2 trips to db server hence has a overhead) |
| inter nodes joins are very slow on sharded db, Joins also become slow on huge tables | - |
| consistency over availabilty & partition tolerance | C,A,P can be traded according to needs |
SQL
3rd highest salary
SELECT * FROM Employee ORDER BY Salary DESC LIMIT 2,1
order by multiple columns
SELECT *
FROM customers
ORDER BY city, first_name;
It sorts the customer list by the city first and then by the first name.
duplicate table with data : CREATE TABLE foo SELECT * FROM bar
duplicate table without data : CREATE TABLE foo SELECT * FROM bar Limit 0 or CREATE TABLE foo SELECT * FROM bar where 1=0
Distinct : SELECT COUNT(DISTINCT Country) FROM Customers;
find duplicate records:
SELECT OrderID, ProductID, COUNT(*)
FROM OrderDetails
GROUP BY OrderID, ProductID
HAVING COUNT(*)>1
delete duplicates : (Self join)
DELETE FROM contacts where contacts.id in(
SELECT id as duplicates from(
SELECT DISTINCT t2.id FROM contacts as t1
JOIN contacts as t2
WHERE
t1.id < t2.id AND
t1.email = t2.email
) as dup
);
###### OR ###########
Delete t2 FROM contacts as t1
JOIN contacts as t2
WHERE
t1.id < t2.id AND
t1.email = t2.email;
types of commands
-
Data Definition Language : create, drop, truncate, alter, rename
-
Data Query Language : Select
-
Data Manipulation Language : insert, update, delete
-
Data Control Language : grant revoke
-
Transaction Control Language : commit, rollback, savepoint, set transaction
truncate can’t be rolled back. we can rollback delete
Group by
Group By X means put all those with the same value for X in the one group.
Group By X, Y means put all those with the same values for both X and Y in the one group.
eg get total usage of electricity month wise
SELECT YEAR(TransactionDate), MONTH(TransactionDate), SUM(Usage)
FROM YourTable
WHERE (TransactionDate Between [Some Start Date] AND[Some End Date])
GROUP BY YEAR(TransactionDate), MONTH(TransactionDate)
ORDER BY YEAR(Created), MONTH(Created)
Joins
The SQL Joins clause is used to combine records from two or more tables in a database. A JOIN is a means for combining fields from two tables by using values common to each
- INNER JOIN − returns rows when there is a match in both tables.
- LEFT JOIN − returns all rows from the left table, even if there are no matches in the right table.
- RIGHT JOIN − returns all rows from the right table, even if there are no matches in the left table.
- FULL JOIN − returns rows when there is a match in one of the tables.
- SELF JOIN − is used to join a table to itself as if the table were two tables, temporarily renaming at least one table in the SQL statement.
- CARTESIAN JOIN − returns the Cartesian product of the sets of records from the two or more joined tables.
Trigger
A trigger is a stored procedure in database which automatically invokes whenever a special event in the database occurs.
create trigger [trigger_name]
[before | after]
{insert | update | delete}
on [table_name]
[for each row]
[trigger_body]
eg:
create trigger stud_marks
before INSERT
on
Student
for each row
set Student.total = Student.subj1 + Student.subj2 + Student.subj3, Student.per = Student.total * 60 / 100;
print 1 to 10
select rownum from dual where rownum<=10;
or
SELECT TOP 10 ROW_NUMBER() FROM sys.objects;
any table with more than 10 rows will do.
procedures
delimiter //
create procedure disp_gender(INOUT mfgender integer, IN emp_gender varchar(6))
-> begin
-> select COUNT(gender)
INTO mfgender FROM author where gender = emp_gender;
-> end; //
delimiter ;
call disp_gender(@M, "Male");
select @M;
call disp_gender(@F, "Female");
select @F;
DROP PROCEDURE LoopDemo;
DELIMITER $$
CREATE PROCEDURE LoopDemo()
BEGIN
DECLARE x INT;
DECLARE str VARCHAR(255);
SET x = 1;
SET str = '';
loop_label: LOOP
IF x > 10 THEN
LEAVE loop_label;
END IF;
SET x = x + 1;
IF (x mod 2) THEN
ITERATE loop_label;
ELSE
SET str = CONCAT(str,x,',');
END IF;
END LOOP;
SELECT str;
END$$
DELIMITER ;
CALL LoopDemo();
cursors : https://www.mysqltutorial.org/mysql-cursor/
Procedures Vs Functions
| Functions | Procedures |
|---|---|
| A function has a return type and returns a value. | A procedure does not have a return type. But it returns values using the OUT parameters. |
| You cannot use a function with Data Manipulation queries. Only Select queries are allowed in functions. | You can use DML queries such as insert, update, select etc… with procedures. |
| A function does not allow output parameters | A procedure allows both input and output parameters. |
| You cannot manage transactions inside a function. | You can manage transactions inside a function. |
| You cannot call stored procedures from a function | You can call a function from a stored procedure. |
| You can call a function using a select statement. | You cannot call a procedure using select statements. |

